Analysis: code duplication change across open-source codebases
Published: June 12, 2026 | Updated: June 18, 2026
Introduction
AI is widely used for coding, and it is commonly believed that AI introduces code duplication. This implies code duplication should increase on average in recent years. My analysis is an attempt to verify that claim.
Summary
My analysis didn't confirm this claim. I was unable to observe any trends, there are large differences between projects and the average hides more than it shows.
But it demonstrates something even more important: how difficult it is to perform an accurate analysis and how easy it is to draw the wrong conclusions.
Methodology
Duplicate detection
AI tools are known for re-implementing the same logic multiple times, not copy-pasting code like humans. That's why code units are compared using an embedding model, and those above a certain similarity threshold are considered as similar. Exact copies were completely excluded from the analysis as not relevant here.
Project selection
14 established open-source projects are included, those with stable architecture, process, and quality requirements. They differ by programming language, size, and type. Only active projects with a longer history, at least from 2021. This aims to reflect an average well-maintained project, not new projects created only by AI tools.
Calculations
For every project, the percent of similar code was calculated at 6 time points across years 2021-2026 on 1st of June every year.
The raw percent of similar code is highly dependent on the project. That's why this value can't be compared between projects. Instead, change relative to the 2021 baseline was calculated. For example, if a project has 10% similar code in 2021 and 15% in 2024, it means that in 2024 it increased by 50%, not by 5 points.
For this type of data, the geometric mean should be calculated as the average. If one project doubles (+100%) and another drops by half (−50%), the average should be zero. But the arithmetic mean reports +25%. The arithmetic mean is calculated only to demonstrate the difference.
Results
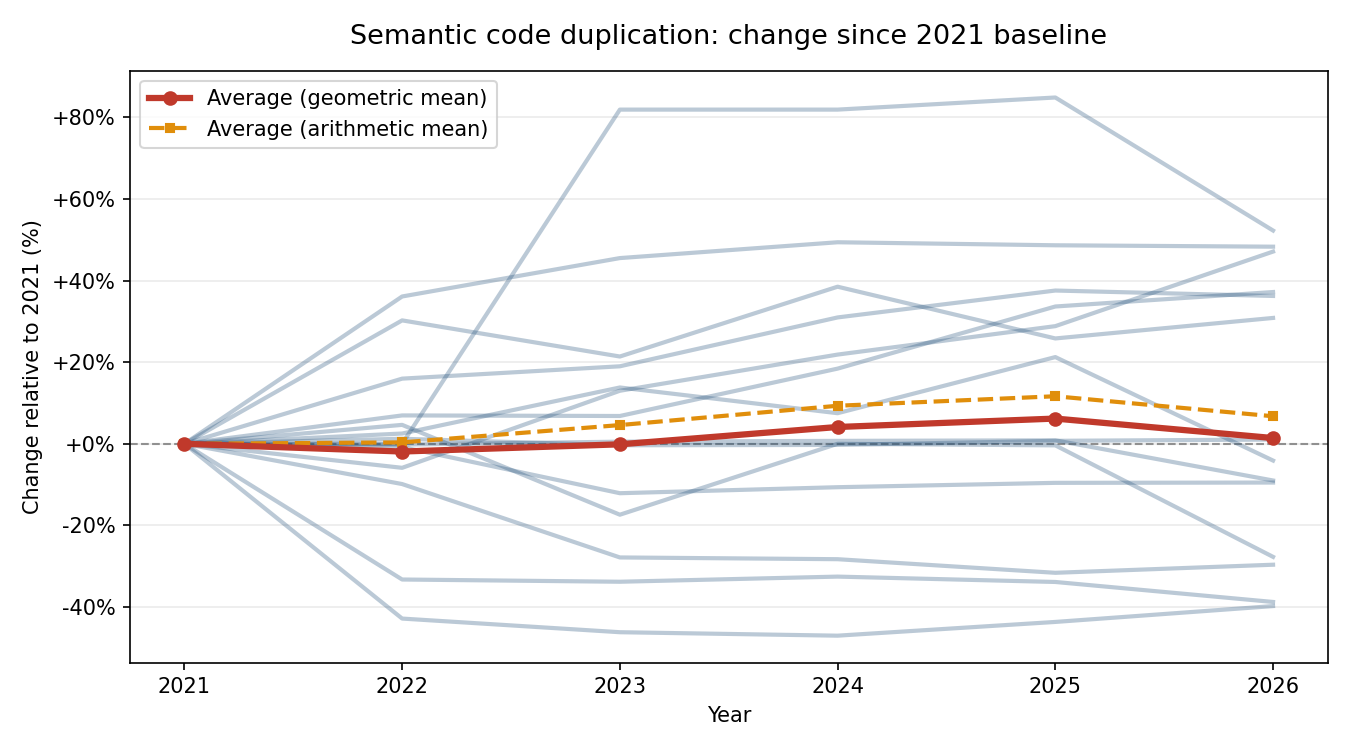
All 14 projects individually plus averages. The baseline is 2021, and every year represents a change relative to this baseline.
Limitations and conclusions
14 projects are too few to prove any global trend, but looking at individual projects allows to see how they differ. Average misses this information. Average in 2026 is the same as 2021, but it doesn't mean everything is flat. There are projects where code duplication has increased, decreased, remained stable, or fluctuated in different directions.
Data shows a change in embedding-based code similarity. Not every similar code is a duplicate. Even exact-copy code is not always unwanted. A change in the percent of duplicated code can have many reasons.
My results don't prove that AI doesn't increase code duplication. It only demonstrates that my methodology plus project type can't show any trend. New projects created only with AI tools don't have a pre-AI baseline, so they need to be analyzed differently.
There are multiple potential pitfalls in analyses in this area leading to wrong conclusions, for example:
- The arithmetic mean shows a duplication increase since 2023 that fits well with an AI narrative, but this is a wrong metric.
- Because of large variability between projects, project selection influences final results.
- Even if the average across a large set would show a clear trend, it doesn't reflect a typical project. Many projects could go in the opposite direction.
- The way duplicated code is detected changes results.
Resources
- github.com/rafal-qa/slopo - Tool used for code duplication analysis (version 0.1.0 with default thresholds).
- data.md - Raw results with projects used, Slopo configuration, and information about excluded exact-copy units.
- chart.py - Python script used for calculations and chart generation.